This was part of madeinportugal.store (mips), a marketplace for sustainable local Portuguese products built by 150 developers across 35 teams. As any ecommerce platform faces, users encounter a common problem: too many products to browse and not enough time to find the right ones. Our team was tasked with solving this through a recommendation microservice — an independent service that would personalize the shopping experience and help users discover products they actually want.
The vision was ambitious: build a system smart enough to learn from real user behavior, fast enough to serve recommendations instantly, and flexible enough to keep improving as it learns more about each user. The goal was to transform recommendations from a nice-to-have feature into a core capability that drives engagement and increases sales.

What We Built #
The recommendation system has three core capabilities that work together to create personalized suggestions. First, it learns from what users rate and review, understanding which types of products appeal to them through explicit feedback. Second, it learns from purchase history, capturing what users actually buy rather than just what they say they like. Third, it learns from wishlists, recognizing products users are interested in but haven’t committed to buying yet.
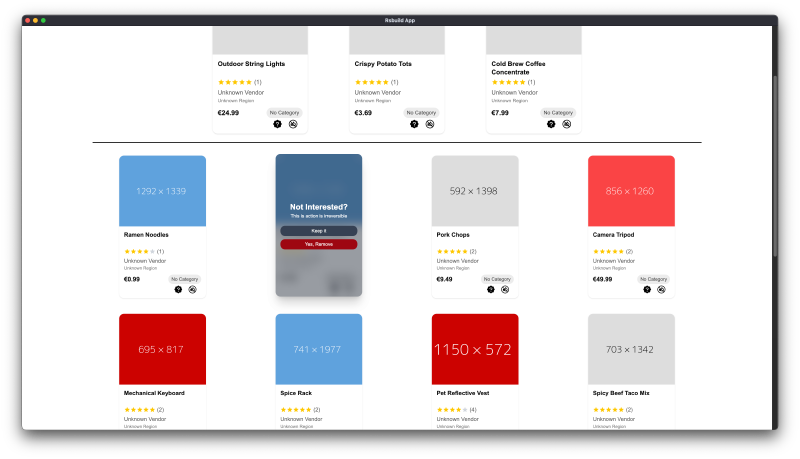
Beyond just making recommendations, the system lets users take control. If a suggestion doesn’t fit their interests, they can mark it as “Not Interested” and the system learns from that feedback too — it won’t show that product or similar ones again. Over time, this user feedback makes recommendations increasingly accurate and relevant.
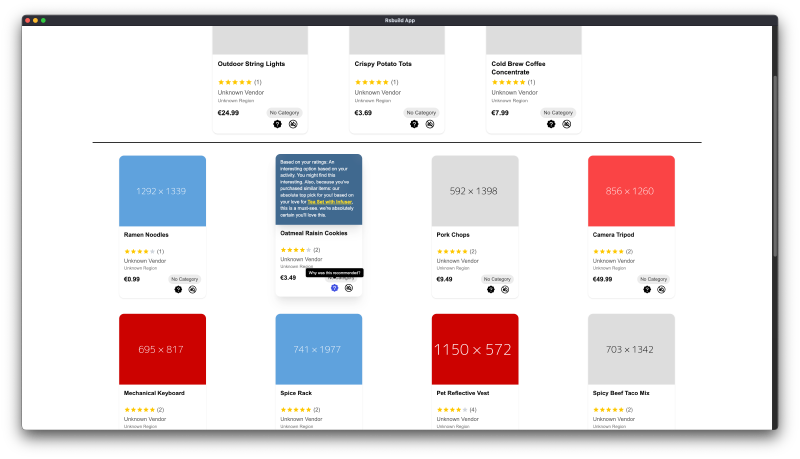
The system also explains why it recommends something. If three separate data sources point to a product being a good fit, the system tells the user exactly which types of signals led to that recommendation. This transparency builds trust and helps users understand the logic behind suggestions.
Here’s what the system looks like in action:
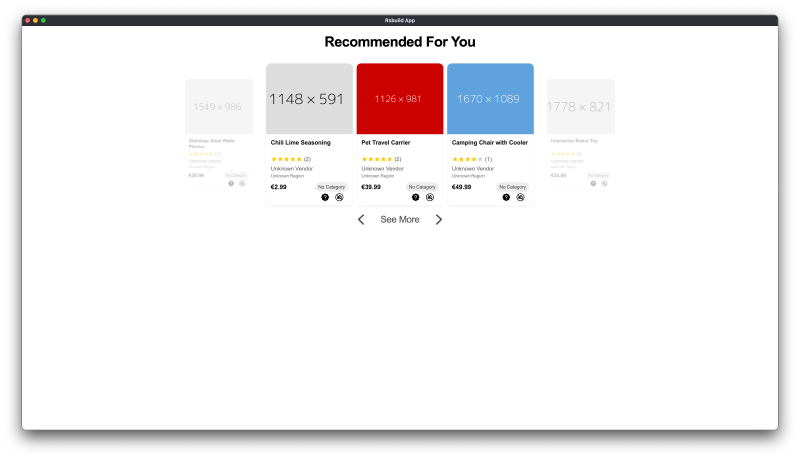
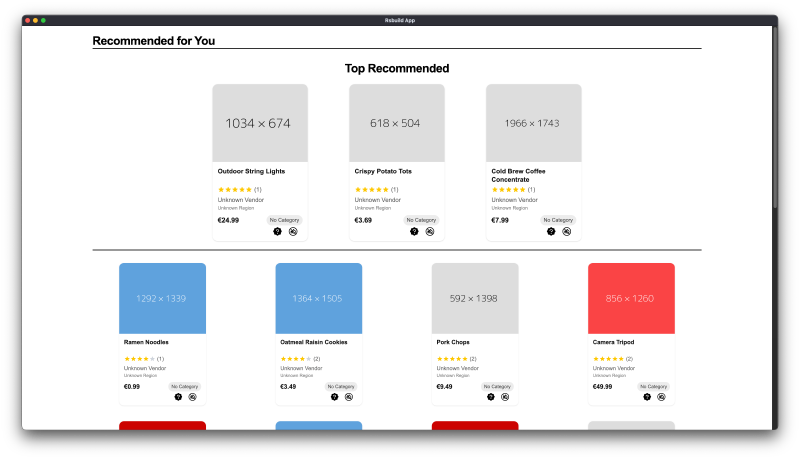
How We Did It #
The Multi-Model Approach
We decided early on to use a multi-model approach rather than betting everything on a single recommendation algorithm. This meant training three separate machine learning models in parallel, each specializing in a different type of user signal. By combining insights from all three, we could make more robust recommendations that didn’t miss opportunities when data was incomplete. We called this ML training component “Surprise” after the surprise library we used — it provided excellent tools for building collaborative filtering models with minimal overhead.
Speed Through Pre-Computation
To keep recommendations instant, we built the system to pre-compute personalized suggestions every night at 2 AM. These pre-computed recommendations are stored in Redis, an ultra-fast cache. When a user visits the site and asks for suggestions, the API responds instantly by serving from this cache — no complex calculations needed during peak hours. This nightly batch window also allowed us to use more sophisticated training techniques without affecting user experience.
Staying Current With Real-Time Data
But here’s where the design gets clever: data collection happens continuously throughout the day. Every review, purchase, and wishlist change is captured in real-time. This continuous data stream feeds into the next morning’s retraining. We limit each model to the last 50 interactions per user per activity type (reviews, purchases, wishlists) — this ensures the models focus on recent behavior and gives us better accuracy while keeping performance snappy.
The result is a hybrid approach: predictions that are instant (served from pre-compute) while staying current with the latest information (trained on yesterday’s fresh data). The service also listens to real-time event streams from across the marketplace, so while the formal model retraining happens once daily, the system is continuously aware of what’s changing and can immediately incorporate new signals in its cached recommendations.
Technical Details #
The system uses three separate machine learning models, each trained on different user signals. The reviews model learns from product ratings between 1-5 stars, capturing direct preferences from users who take the time to review. The purchase model learns from order history, treating purchases as a strong signal of preference even if users never leave reviews. The wishlist model learns from saved items, recognizing that wishlists indicate interest even when purchases haven’t happened yet.
These three models don’t carry equal weight. When making recommendations, reviews and purchases together influence 60% of the decision while wishlists influence 40%. This weighting reflects the reality that explicit actions like buying or rating carry more signal than saving for later. When all three sources point toward a recommendation, the system provides a detailed explanation showing which signals triggered it.
The system also handles the cold-start problem — when new users or new products first arrive without much data, the system requires a minimum number of interactions (at least 2-3 per activity type) before making confident recommendations. Once that threshold is met, the models can start generating predictions.
One sophisticated feature is how we handle “Not Interested” feedback. When users mark a product as not interested, we don’t just hide that specific item. Instead, the “Not Interested” items flow into a separate similarity detection algorithm that identifies and excludes related products from future recommendations. This ensures users don’t see products similar to ones they’ve already rejected, maintaining genuine variety in what they’re shown.
Every night, the entire training pipeline runs automatically. All three models retrain on fresh data (using each user’s last 50 interactions per activity type), process every active user, apply the smart filtering for “Not Interested” items, generate up to 50 recommendations per user with explanations, and refresh everything in the cache by morning. Throughout the day, new data continues to be collected in real-time, ready for tomorrow’s retrain.
Architecture #
The system is split into distinct components that work together seamlessly. Understanding each piece makes it clear how data flows from user interactions to personalized recommendations.
Data Sources feed the system with raw information. The Jumpseller API provides product catalog data from the store. Google Pub/Sub streams real-time events (reviews, orders, wishlist changes, user updates) from across the marketplace. The Cloud SQL database stores all historical data for training and reference.
Data Processing transforms raw events into training-ready formats. The Data Transformer component cleans incoming data and prepares it for the machine learning models. This ensures that all three models receive consistent, high-quality input data.
Model Training is where the intelligence happens. The Surprise Wrapper (our wrapper around the Surprise library) does the actual computation work, training our three specialized machine learning models. The Model Trainer orchestrates this entire flow and schedules it to run automatically every night at 2 AM.
Serving gets recommendations to users instantly. Redis (our in-memory cache) stores pre-computed recommendations indexed by user ID. The Recommendation API is what the frontend calls when users visit the store — it’s the gateway between user requests and cached results. The Recommendation Generator fetches cached suggestions and enriches them with current product details.
When a user visits, the flow is straightforward: the frontend asks “What should I show this user?” and the Recommendation Controller handles the request. It immediately checks the cache for pre-computed recommendations. If they exist, they’re returned instantly with complete product information. If recommendations aren’t found, it means the user hasn’t accumulated enough activity data yet, so the frontend displays a message encouraging them to interact with the store.
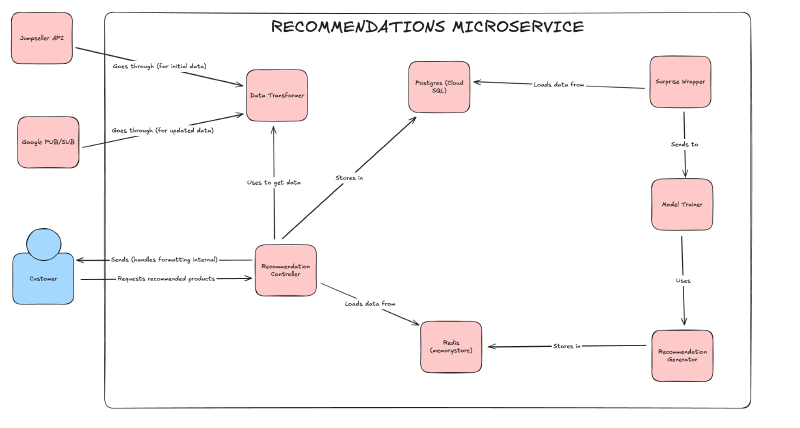
The diagram above shows how these components orchestrate inside the recommendation microservice. Data flows in from Jumpseller API and Pub/Sub through the Data Transformer, gets stored in Cloud SQL, flows into model training via the Surprise Wrapper and Model Trainer, and finally gets stored in Redis for instant retrieval when the Recommendation API needs it.
Integration with Other Microservices #
The recommendation system doesn’t operate in isolation; it’s tightly integrated into the larger marketplace ecosystem through Google Pub/Sub. Rather than repeatedly asking other services “Has anything changed?”, we subscribe to events from across the platform: new reviews, purchases, wishlist updates, product changes, user registrations, and seller onboarding. Each event is captured immediately and stored for the next morning’s retraining cycle.
This event-driven approach keeps the system loosely coupled from other services — the recommendation microservice doesn’t need direct dependencies on review services, order services, or user management. It simply listens and reacts. This architecture scales well as the marketplace grows and new microservices are added; they just need to publish their events to the same Pub/Sub topics.
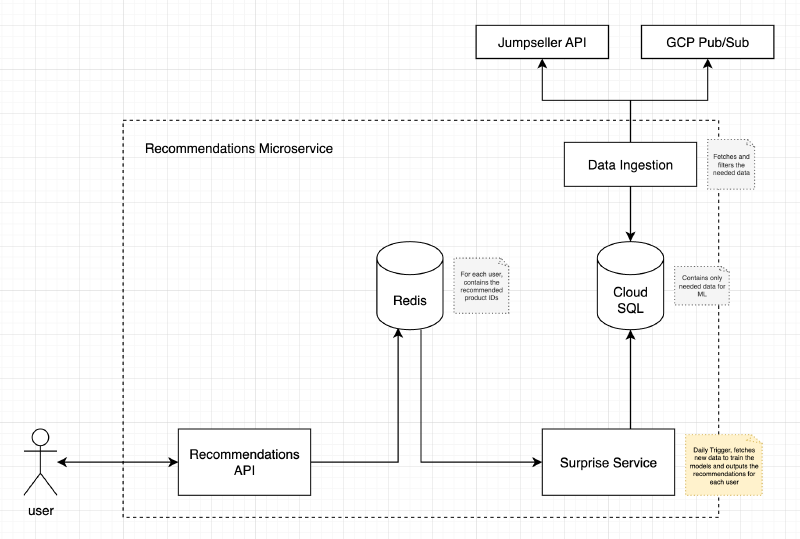
This diagram shows how the Surprise Service listens to multiple event streams and pulls data from Jumpseller, then outputs trained models back into Redis for the Recommendation API to serve.
Why It Matters #
At the user level, the impact is straightforward. Products feel handpicked rather than random. Instead of endless scrolling through irrelevant items, users see suggestions tailored to their actual interests. They maintain control through “Not Interested” feedback, gradually shaping recommendations to match their evolving preferences.
For the marketplace, recommendations create measurable business value. Users who see relevant suggestions stay longer on the platform and explore more products. They’re significantly more likely to find and purchase items that genuinely interest them. Better recommendations directly translate to higher engagement and conversion rates.
From a technical perspective, the system is built to handle real scale. It can serve thousands of users across millions of products without breaking. Updates happen automatically every night, requiring minimal manual intervention. The entire architecture is monitored for problems, with automatic error detection and logging so the team knows immediately if something goes wrong.
The technical sophistication under the hood — three specialized ML models working in concert, real-time data synchronization, sub-millisecond caching, and continuous monitoring — makes all of this possible. What users experience as simple, fast, and accurate recommendations is actually the product of careful architecture, thoughtful algorithm design, and meticulous integration with a complex distributed system.